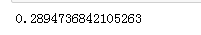import os all_folds = os.listdir(r'C:\Users\Administrator\Desktop\源数据-分析\lfw_funneled')###https://www.kaggle.com/atulanandjha/lfwpeople?select=pairs.txt all_folds = [x for x in all_folds if'.'notin x] import pandas as pd numbers_img=pd.DataFrame(columns=["文件名称","图片数量"])####统计各个文件夹里面的图片数量 for i inrange(len(all_folds)): path = 'C:\\Users\\Administrator\\Desktop\\源数据-分析\\lfw_funneled\\'+all_folds[i] all_files = os.listdir(path) numbers_img.loc[i]=[all_folds[i],len(all_files)] img_10=numbers_img[numbers_img["图片数量"]==10].reset_index()#####为了降低数据偏斜,选取图片数量为10的文件(否则,特征提取会被图片数量过多的数据影响) from PIL import Image import numpy as np image_arr_list=[]###存放灰度值numpy数组 flat_arr_list=[]###存放灰度值一维数组 target_list=[]###存放目标值 for m inrange(len(img_10["文件名称"])): file_address='C:\\Users\\Administrator\\Desktop\\源数据-分析\\lfw_funneled\\'+img_10["文件名称"][m]+"\\"####指定特定的文件地址 image_name=os.listdir(file_address)###获得指定文件夹下的左右文件名称 for n in image_name: image=Image.open(file_address+n) image=image.convert('L')###RGB(红绿蓝)像素值转换成灰度值 image_arr=np.array(image,"f")###灰度值转化成numpy数组(二维) flat_arr=image_arr.ravel()###将数组扁平化处理,返回的是一个一维数组的非副本视图,就是将几行的数据强行拉成一行 image_arr_list.append(image_arr) flat_arr_list.append(flat_arr) target_list.append(m)###这里的m设定是数字,如果是文本的话后面的算法会报错 faces_dict={"images":np.array(image_arr_list),"data":np.array(flat_arr_list),"target":np.array(target_list)}